/** * This immutable data type represents a tweet from Twitter. */ publicclassTweet{
public String author; public String text; public Date timestamp;
/** * Make a Tweet. * @param author Twitter user who wrote the tweet * @param text text of the tweet * @param timestamp date/time when the tweet was sent */ publicTweet(String author, String text, Date timestamp){ this.author = author; this.text = text; this.timestamp = timestamp; } }
对于这个结构,我们在创建之后可以任意访问修改它的字段,因为字段被声明为public:
1 2 3 4
Tweet t = new Tweet("justinbieber", "Thanks to all those beliebers out there inspiring me every day", new Date()); t.author = "rbmllr";
你可能会想:为什么改变一个对象的字段被认为是一种“泄露”呢?我们从软件构造的3个角度来回答:
safe from bug: 通过赋值改变一个字段可能会导致错误,例如赋值不匹配的类型或无意义的类型。
esay to understand: 赋值一个字段的行为可能是令人困惑的,尤其是当各个字段的含义并不是那么清楚的时候。
ready for change:一旦对象的内部表示发生变化,所有的赋值都必须手动重写。如果用方法进行赋值,则可以很方便的重构。
/** @return a tweet that retweets t, one hour later*/ publicstatic Tweet retweetLater(Tweet t){ Date d = t.getTimestamp(); d.setHours(d.getHours()+1); returnnew Tweet("rbmllr", t.getText(), d); }
/** @return a list of 24 inspiring tweets, one per hour today */ publicstatic List<Tweet> tweetEveryHourToday(){ List<Tweet> list = new ArrayList<Tweet>(); Date date = new Date(); for (int i = 0; i < 24; i++) { date.setHours(i); list.add(new Tweet("rbmllr", "keep it up! you can do it", date)); } return list; }
/** * Make a Tweet. * @param author Twitter user who wrote the tweet * @param text text of the tweet * @param timestamp date/time when the tweet was sent */ publicTweet(String author, String text, Date timestamp){ this.author = author; this.text = text; this.timestamp = timestamp; }
为此,我们在接收引用时也要使用防御式拷贝。如下所示:
1 2 3 4 5
publicTweet(String author, String text, Date timestamp){ this.author = author; this.text = text; this.timestamp = new Date(timestamp.getTime()); }
erpc_status_tTCPTransport::underlyingReceive(uint8_t *data, uint32_t size){ ssize_t length; erpc_status_t status = kErpcStatus_Success;
// Block until we have a valid connection. while (m_socket <= 0){ Thread::sleep(10000); } // Loop until all requested data is received. while (size > 0U){ length = read(m_socket, data, size);
// Length will be zero if the connection is closed. if (length > 0){ size -= length; data += length; }else{ if (length == 0){ // close socket, not server close(false); status = kErpcStatus_ConnectionClosed; }else{ status = kErpcStatus_ReceiveFailed; } break; } } return status; }
funcNewServer(opt ...ServerOption) *Server { //用option模式指定各个服务器选项 opts := defaultServerOptions for _, o := range extraServerOptions { o.apply(&opts) } for _, o := range opt { o.apply(&opts) }
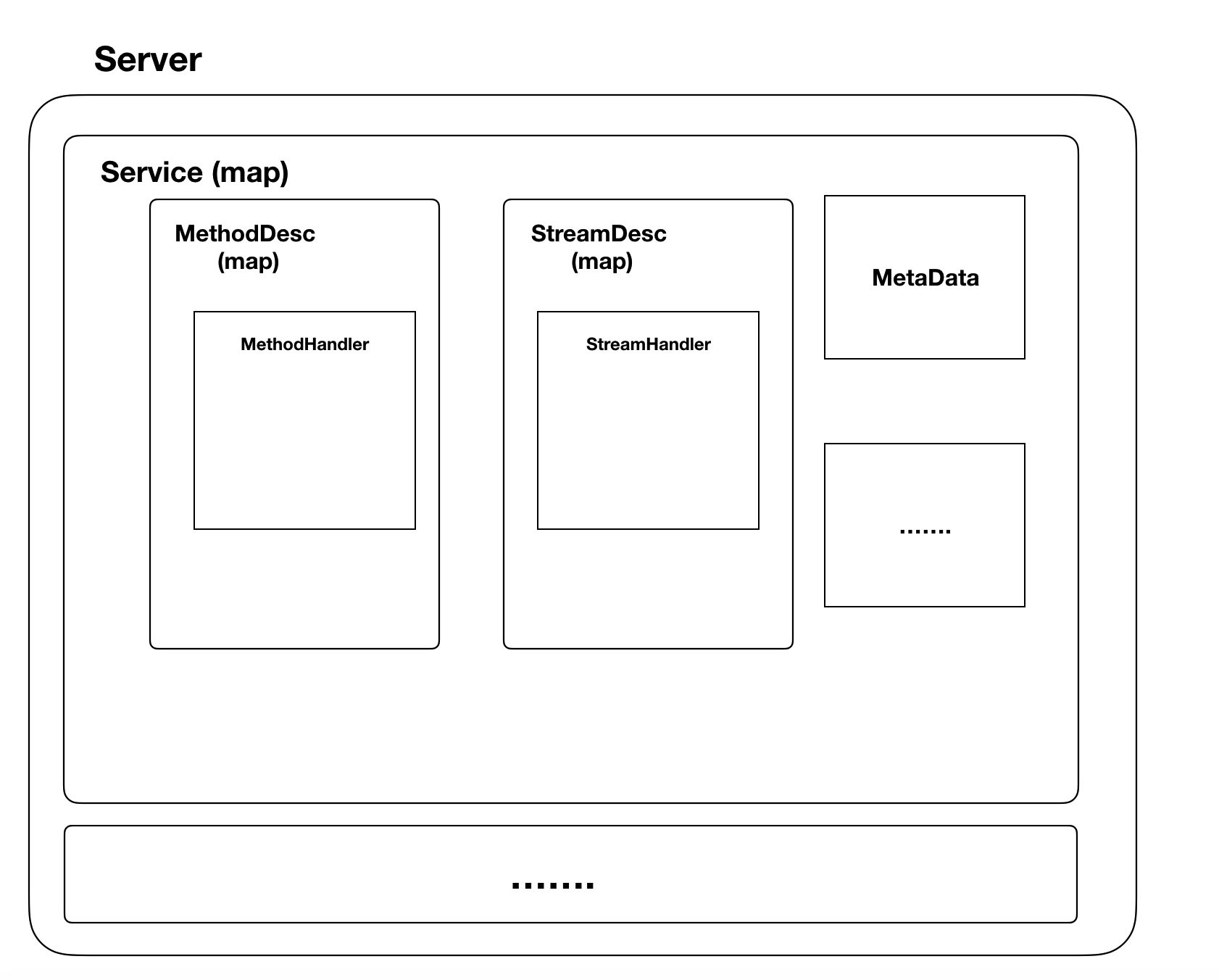
// serviceInfo wraps information about a service. It is very similar to // ServiceDesc and is constructed from it for internal purposes. type serviceInfo struct { // Contains the implementation for the methods in this service. serviceImpl interface{} methods map[string]*MethodDesc streams map[string]*StreamDesc mdata interface{} }
// GreeterServer is the server API for Greeter service. // All implementations must embed UnimplementedGreeterServer // for forward compatibility type GreeterServer interface { // Sends a greeting SayHello(context.Context, *HelloRequest) (*HelloReply, error) mustEmbedUnimplementedGreeterServer() }
// RegisterService registers a service and its implementation to the gRPC // server. It is called from the IDL generated code. This must be called before // invoking Serve. If ss is non-nil (for legacy code), its type is checked to // ensure it implements sd.HandlerType. func(s *Server)RegisterService(sd*ServiceDesc, ss interface{}) { // 检查类型 if ss != nil { ht := reflect.TypeOf(sd.HandlerType).Elem() st := reflect.TypeOf(ss) if !st.Implements(ht) { logger.Fatalf("grpc: Server.RegisterService found the handler of type %v that does not satisfy %v", st, ht) } } s.register(sd, ss) }
func(s *Server)register(sd *ServiceDesc, ss interface{}) { // 加锁 s.mu.Lock() defer s.mu.Unlock() // 打印日志 s.printf("RegisterService(%q)", sd.ServiceName) // 检查异常 if s.serve { logger.Fatalf("grpc: Server.RegisterService after Server.Serve for %q", sd.ServiceName) } if _, ok := s.services[sd.ServiceName]; ok { logger.Fatalf("grpc: Server.RegisterService found duplicate service registration for %q", sd.ServiceName) } // 将sd中的内容注入到serviceinfo中,并将ss类型保存为serviceImpl info := &serviceInfo{ serviceImpl: ss, methods: make(map[string]*MethodDesc), streams: make(map[string]*StreamDesc), mdata: sd.Metadata, } for i := range sd.Methods { d := &sd.Methods[i] info.methods[d.MethodName] = d } for i := range sd.Streams { d := &sd.Streams[i] info.streams[d.StreamName] = d } s.services[sd.ServiceName] = info }
server 对不同 rpc 请求的处理,也是根据 service 中不同的 serviceName 去 service map 中取出不同的 handler 进行处理,这样相当于完成了grpc的代理操作,把字符串传递给代理,代理就能调用对应的实际方法去处理。
// 返回错误信息 return err } tempDelay = 0 // Start a new goroutine to deal with rawConn so we don't stall this Accept // loop goroutine. // // Make sure we account for the goroutine so GracefulStop doesn't nil out // s.conns before this conn can be added. s.serveWG.Add(1) gofunc() { s.handleRawConn(lis.Addr().String(), rawConn) s.serveWG.Done() }() } }
// handleRawConn forks a goroutine to handle a just-accepted connection that // has not had any I/O performed on it yet. func(s *Server)handleRawConn(lisAddr string, rawConn net.Conn) { // 检查是否退出 if s.quit.HasFired() { rawConn.Close() return } // 设置一次IO操作的最大时间,如果超过直接失败 // 这里是用来限制连接时间的 rawConn.SetDeadline(time.Now().Add(s.opts. connectionTimeout))
// Finish handshaking (HTTP2) st := s.newHTTP2Transport(rawConn)
// 完成连接之后取消时长限制 rawConn.SetDeadline(time.Time{}) if st == nil { return }
// newHTTP2Transport sets up a http/2 transport (using the // gRPC http2 server transport in transport/http2_server.go). func(s *Server)newHTTP2Transport(c net.Conn)transport.ServerTransport { config := &transport.ServerConfig{ ... } st, err := transport.NewServerTransport(c, config) if err != nil { ... }