这是一条置顶公告。
如果要查看为OS课程专门写作的博客,可以在带有ISA tag的文章中查看相关读书笔记。
未命名
INTEL指令集手册笔记-x86体系结构概览
▶︎
all
running...
写在最开始
本文是基于IA-32架构软件开发者手册(第三卷)的阅读笔记。作为软件开发者,这或许是我们所必须掌握的知识中最接近底层的一部分。在这里,我们将会看到计算机是如何工作的,以及我们的程序是如何被计算机执行的。
这些内容十分的抽象、晦涩、冗杂,包含了大量的细节和术语。因此,我将会尽量使用简单的语言来描述这些内容。
大多数时候,我使用无序列表来展示一些重要的概念,以期尽量精简的展示系统的结构。在开头和结尾,总是会有概括性的文字对于这部分内容进行概述和总结。对于特别重要或特别复杂的部分,我才会使用成段的文字展开讨论。我从不罗列内容,例如EFLAGS每个位置的含义,而只用文字解释图片中没有的信息。不过,我仍然会列出重要的几点供读者强化记忆。
为了更好的理解这部分知识,我们首先需要对一些关键的术语(主要是中文术语)进行辨析,理清这些内容,对于我们理解之后的内容有很大帮助。下面的内容假设读者具有一定的汇编和体系结构方面的知识(比如学习过CSAPP)。
关于“模式”
在Intel处理器中,存在许多的“模式”。我们将会看到,这些模式对应不同的寻址方式和内存布局。文中出现的模式大概有以下几种:
-
实模式:最早的模式,也是(目前)所有处理器启动时的默认模式。这种情况下,表示为
CS:IP的地址值为CS<<4 + IP。至多管理1MB的内存。这是8086 16位体系结构的无奈之举,用这种方式配合20位地址总线,编程空间得以从令人难以忍受的64KB扩展到1MB。
-
IA32(保护模式):从80386开始启用的模式,这种情况下,可以用平坦分段管理至多4GB的内存
-
IA32e(长模式):支持64位的体系结构。提供至多48位的地址空间,并提供兼容32位OS和软件的“兼容模式”。不再使用段寄存器,段选择子固定为GDT,几乎完全采用页式地址管理。
值得注意的是,IA32e与IA64并不相同。前者是我们熟知的x86-64(有时也称为x64)体系结构的一部分,是目前主流的64位体系结构。而IA64则是一种激进的不兼容IA32的64位架构,由Intel与HP合作开发,目前已经被抛弃。
关于“地址空间”
我们知道,在计算机界为人津津乐道的(八股文)术语之一就是地址空间,逻辑地址、线性地址、虚拟地址、物理地址成为无数求职者和学子的噩梦。
-
物理地址(Physical Address,PA):这个术语常常表示数据在物理内存条中的位置。在现代系统中,物理地址是由MMU(内存管理单元)通过页表变换得到的。
-
线性地址(linear address):这个术语通常用来描述理想状态下的连续地址空间。 当我说“线性地址”时,我总是指的是CPU使用的地址。
维基百科:线性地址
-
逻辑地址(logical address):这个术语通常用来描述“分段模式下”的
段基址:偏移量形式的地址。不过,它的本意实际上是“编程时使用的地址”。从这个角度来说,逻辑地址其实等同于线性地址。维基百科:地址空间
-
虚拟地址(Virtual Address,VA):这个术语常常表示进程所看到的内存空间。由于保护模式和长模式的现代系统总是使用页表基址提供给进程一个完整的连续地址空间,虚拟地址也就等同于线性地址。
对于实模式而言,很难谈论虚拟地址,有人认为虚拟地址等于段偏移量,有人认为虚拟地址等于逻辑地址,但这其实没有意义。
MSDB: 虚拟地址
以上的讨论仅限于本文,如果面试的时候被问到,请回答“逻辑地址经过段式变换得到线性地址,进程看到的线性地址(通过页表管理的线性地址)就是虚拟地址,虚拟地址经过页式变换得到物理地址”。
体系结构概览
本章中,我们将关注系统的寄存器结构以及操作这些寄存器的系统指令。理解寻址、内存、中断处理、任务管理的机制以及其中的重要数据结构。并且看到计算机是如何从实模式切换到保护模式的。
系统级寄存器和数据结构
下图展示了保护模式和长模式下的系统寄存器和数据结构。其中:
- 左上角的部分展示了寄存器,包括标志寄存器、控制寄存器、任务寄存器和其他通用寄存器
- TODO:
- 底部展示了页表将线性地址映射到物理地址的方式

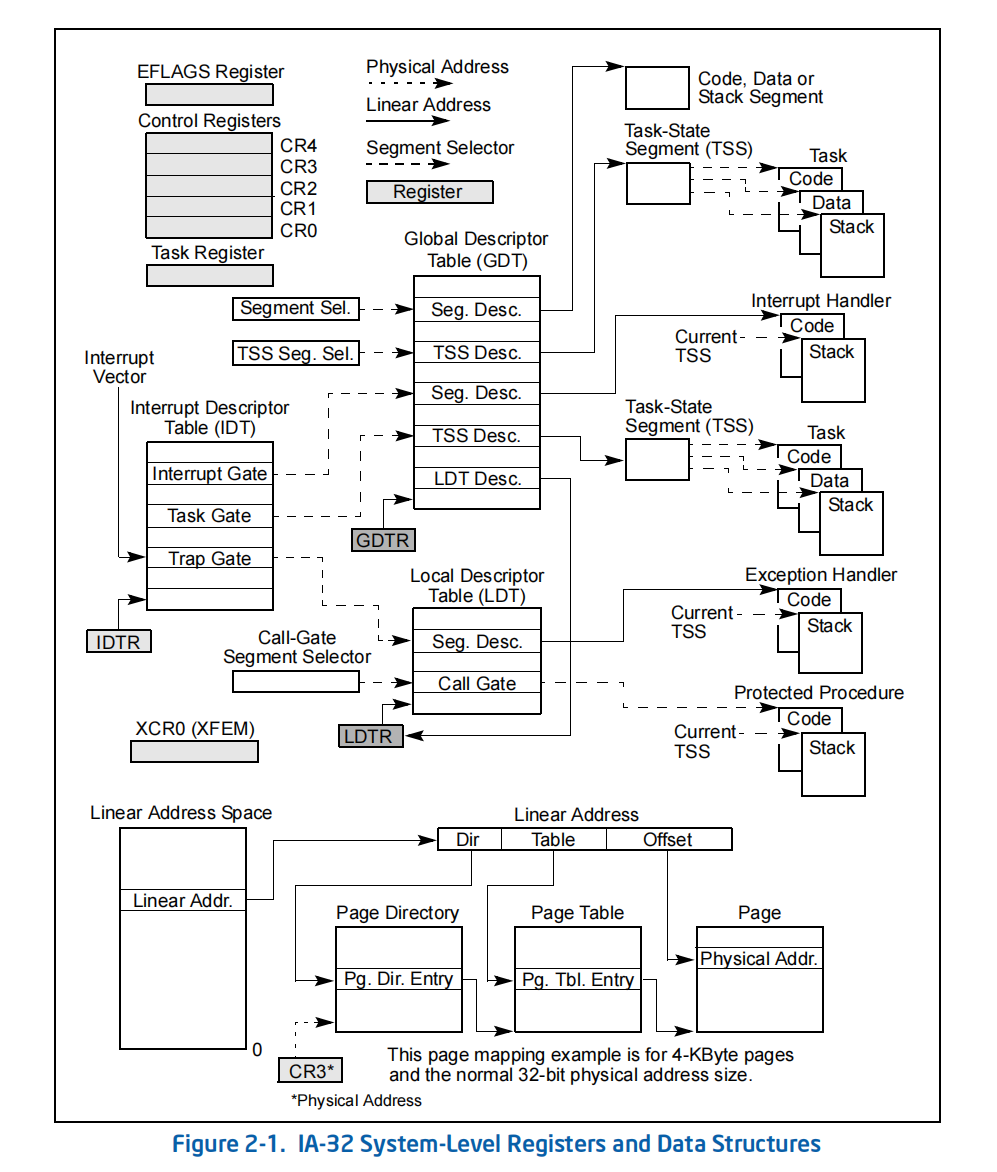
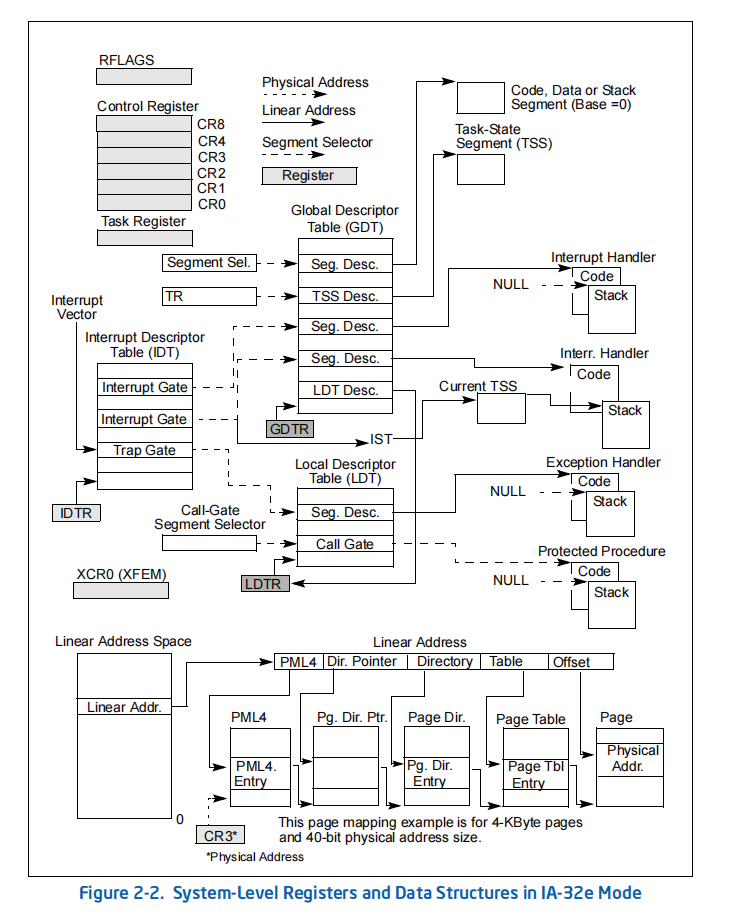
左:保护模式(IA32)下的系统寄存器和数据结构
右:长模式(IA32e)下的系统寄存器和数据结构
1. 全局描述符表(GDT)和局部描述符表(LDT)
在保护模式下,所有访存都是通过描述符表——GDT和LDT完成的。
-
描述符表(Descriptor Table,DT):用于内存、中断、任务管理的重要数据结构。
-
段描述符(Segment descriptors):描述符表的表项。定义了段的起始地址、访问权限(读写执行)和使用信息。
-
段选择子(Segment Selector):用来在GDT或LDT中定位段描述符。包含相对于DT基址的偏移量,一个全局/局部标志位,以及特权级。
-
描述附表寄存器(Descriptor Table Register,DTR):用来存储DT的线性地址基址。
当前特权级(Current privilege level,CPL):当前正在执行的代码所在的特权级。通常,特权级别从0~3,0表示内核态(完全权限),3表示用户态(最低权限)。
通过段选择子查询DT可以访问代码、数据、栈等段,其中的权限标志会阻止不合法的访问。
长模式下描述符扩展为16字节,兼容模式下不进行这种扩展
描述符机制是段式地址管理在现代系统中的实现,这种机制方便了内存的管理,并且提供了访问权限的控制。实模式下,总是直接访问物理地址,而保护模式下则至少要经过描述符的转换。从这个角度上来说,“实”指的是直接访问物理地址,“保护”指的是通过描述符表进行访问权限的保护。
2.系统段,段描述符和门
-
系统段:TSS(Task-state Segment)和LDT,称为系统段。其余的则是运行时环境包含的代码、数据、栈这等段。GDT不视作系统段因为其不通过段选择子访问。
-
门(Gate):特殊的段选择子,通过门进行的调用可以进行特权级别的转换。包含过程调用、中断、陷阱、任务等。
- 调用门:可以执行更高特权级别的代码,还可用于16-32位代码段的相互访问。
长模式下,调用门可以用于64位和32位模式的代码段的相互访问。任务切换门被设置为NULL,其余门(包括TSS选择子和LDT选择子)被扩展为16字节。不过,页表中的特权控制很大程度上代替了门的特权控制功能。如同之前一样,段描述符和门都是在保护中重要,而在长模式中不再重要的概念。
门的使用方式和段选择子类似,通过门选择子查询GDT或LDT中的门描述符以获取基址,然后结合偏移量访问对应的数据。不过,门提供了特权级别的转换甚至是字长模式的转换,因而是一种特殊的段描述符。
系统段,称其为“系统”,是相对于“应用”而言的。系统段的存在是为了支持操作系统的运行,包括任务上下文保存、地址管理、中断处理等。
3.任务状态段(Task-State Segment)和任务门(Task Gates)
任务状态段包含了一个任务所需的上下文:
- 通用寄存器
- 条件码:EFLAGS
- 程序计数器:EIP
- 堆栈指针(3个特权级各一个)
- 页表基址寄存器(CR3)
- 局部描述符表选择子
每次任务切换,操作系统都要保存状态,通过GDT选择新TSS并加载状态。
任务状态段要么通过TSSs(任务状态段选择子)访问,要么通过任务门访问,后者可以提供特权控制。
长模式下,不再能通过硬件切换任务,因此任务门不再有效。不过TSS仍然保留,且TSSs设置为指向TSS基址。
任务状态段的存在是为了支持任务切换,而任务切换是为了支持多道程序。一个TSS保存的内容就是一个完整的上下文,包括当前的数据、状态、执行位置等基础信息,还包含其地址空间信息(页表基址寄存器和LDT选择子)。
4.中断和异常处理
外部中断(指外设引发的异步中断),软件中断和异常都通过中断描述符表(IDT)进行管理。
- 中断描述符:IDT中的表项,都是门描述符,包含了中断处理程序的地址、特权级别等信息,也可以是一个任务门。
- 中断描述符表寄存器(IDTR):用来存储IDT的线性地址基址。
- 中断向量:中断描述符的索引,通过中断向量查询IDT中的门描述符。
外设、处理器、软件都可以引发中断。软件中断使用INT系列或BOUND指令。三种形式的中断例如:键盘中断、浮点异常、系统调用。
中断和陷阱会的处理等效于通过调用门调用处理函数,而指向任务门的中断向量会通过任务切换调用相应的处理函数。
5.内存管理
处理器支持物理地址或虚拟地址两种模式。分页启动时,所有的访存都是通过页表完成的。
- 分页(Paging):一种地址管理方式,将线性地址按照一定大小(通常是4K)映射到物理地址。这个映射往往是乱序的。
- 页表(Page Table):管理线性地址到物理地址的映射关系的数据结构。
- 页帧(Page Frame):物理内存中的页大小的连续区域。
- 页表基址寄存器:用来存储页表的地址基址,是一个控制寄存器(Control Register,CR),即CR3。
- 页表条目:包含页或下一级页表的基址,以及访问权限等信息。
长模式下的页表分为4级,每级512个条目,每个条目8字节,每个页表恰好占用4K。页表基址寄存器指向最顶级页表的物理地址基址。
6.系统寄存器
- 条件码寄存器(EFLAGS):包含了一些标志位,用来表示上一条指令的执行结果。例如进位标志、溢出标志等。还包含模式切换中断处理等标志
- 控制寄存器(CR):包含了一些控制系统行为的标志位。例如分页开关。
- 任务寄存器(TR):用来存储TSS选择子,用于任务切换。
- 系统寄存器(MSR):包含了一些系统相关的信息。例如时间戳计数器(TSC)。
INTEL 指令集手册-x86体系结构概览
INTEL指令集手册笔记-x86体系结构概览
写在最开始
本文是基于IA-32架构软件开发者手册(第三卷)的阅读笔记。作为软件开发者,这或许是我们所必须掌握的知识中最接近底层的一部分。在这里,我们将会看到计算机是如何工作的,以及我们的程序是如何被计算机执行的。
这些内容十分的抽象、晦涩、冗杂,包含了大量的细节和术语。因此,我将会尽量使用简单的语言来描述这些内容。
大多数时候,我使用无序列表来展示一些重要的概念,以期尽量精简的展示系统的结构。在开头和结尾,总是会有概括性的文字对于这部分内容进行概述和总结。对于特别重要或特别复杂的部分,我才会使用成段的文字展开讨论。我从不罗列内容,例如EFLAGS每个位置的含义,而只用文字解释图片中没有的信息。不过,我仍然会列出重要的几点用于强化记忆。
为了更好的理解这部分知识,我们首先需要对一些关键的术语(主要是中文术语)进行辨析,理清这些内容,对于我们理解之后的内容有很大帮助。下面的内容假设读者具有一定的汇编和体系结构方面的知识(比如学习过CSAPP)。
关于“模式”
在Intel处理器中,存在许多的“模式”。我们将会看到,这些模式对应不同的寻址方式和内存布局。文中出现的模式大概有以下几种:
实模式:最早的模式,也是(目前)所有处理器启动时的默认模式。这种情况下,表示为
CS:IP的地址值为CS<<4 + IP。至多管理1MB的内存。这是8086 16位体系结构的无奈之举,用这种方式配合20位地址总线,编程空间得以从令人难以忍受的64KB扩展到1MB。
IA32(保护模式):从80386开始启用的模式,这种情况下,可以用平坦分段管理至多4GB的内存
IA32e(长模式):支持64位的体系结构。提供至多48位的地址空间,并提供兼容32位OS和软件的“兼容模式”。不再使用段寄存器,段选择子固定为GDT,几乎完全采用页式地址管理。
值得注意的是,IA32e与IA64并不相同。前者是我们熟知的x86-64(有时也称为x64)体系结构的一部分,是目前主流的64位体系结构。而IA64则是一种激进的不兼容IA32的64位架构,由Intel与HP合作开发,目前已经被抛弃。
关于“地址空间”
我们知道,在计算机界为人津津乐道的(八股文)术语之一就是地址空间,逻辑地址、线性地址、虚拟地址、物理地址成为无数求职者和学子的噩梦。
物理地址(Physical Address,PA):这个术语常常表示数据在物理内存条中的位置。在现代系统中,物理地址是由MMU(内存管理单元)通过页表变换得到的。本文中,物理地址并不会频繁的出现,然而,页表基址寄存器(CR3)存储的就是页表的物理地址基址。否则,默认情况下的“地址基址”往往是线性地址。
线性地址(linear address):这个术语通常用来描述理想状态下的连续地址空间。线性地址就是经过段式变换后得到的地址,也就是CPU实际使用的地址。
维基百科:线性地址
逻辑地址(logical address):这个术语通常用来描述“分段模式下”的
段基址:偏移量形式的地址。不过,它的本意实际上是“编程时使用的地址”。从这个角度来说,逻辑地址其实等同于线性地址。维基百科:地址空间
虚拟地址(Virtual Address,VA):这个术语常常表示进程所看到的内存空间。由于保护模式和长模式的现代系统总是使用页表基址提供给进程一个完整的连续地址空间,虚拟地址也就等同于线性地址。
对于实模式而言,很难谈论虚拟地址,有人认为虚拟地址等于段偏移量,有人认为虚拟地址等于逻辑地址,但这其实没有意义。因为实(地址)模式不存在什么虚拟的地址
MSDB: 虚拟地址
综上所述,如果面试的时候被问到,或许可以回答“逻辑地址经过段式变换得到线性地址,如果是启动分页的保护模式或长模式,那么线性地址就是虚拟地址,虚拟地址经过页式变换得到物理地址;如果是实模式,那么没有虚拟地址,线性地址就是物理地址”。
体系结构概览
本章中,我们将关注系统的寄存器结构以及操作这些寄存器的系统指令。理解寻址、内存、中断处理、任务管理的机制以及其中的重要数据结构。并且看到计算机是如何从实模式切换到保护模式的。
系统级寄存器和数据结构
下图展示了保护模式和长模式下的系统寄存器和数据结构。其中:
- 左上角的部分展示了寄存器,包括标志寄存器、控制寄存器、任务寄存器和其他通用寄存器
- TODO:
- 底部展示了页表将线性地址映射到物理地址的方式


左:保护模式(IA32)下的系统寄存器和数据结构
右:长模式(IA32e)下的系统寄存器和数据结构
1. 全局描述符表(GDT)和局部描述符表(LDT)
在保护模式下,所有访存都是通过描述符表——GDT和LDT完成的。
描述符表(Descriptor Table,DT):用于内存、中断、任务管理的重要数据结构。
段描述符(Segment descriptors):描述符表的表项。定义了段的起始地址、访问权限(读写执行)和使用信息。
段选择子(Segment Selector):用来在GDT或LDT中定位段描述符。包含相对于DT基址的偏移量,一个全局/局部标志位,以及特权级。
描述附表寄存器(Descriptor Table Register,DTR):用来存储DT的线性地址基址。
当前特权级(Current privilege level,CPL):当前正在执行的代码所在的特权级。通常,特权级别从0~3,0表示内核态(完全权限),3表示用户态(最低权限)。
通过段选择子查询DT可以访问代码、数据、栈等段,其中的权限标志会阻止不合法的访问。
描述符机制是段式地址管理在现代系统中的实现,这种机制方便了内存的管理,并且提供了访问权限的控制。实模式下,总是直接访问物理地址,而保护模式下则至少要经过描述符的转换。从这个角度上来说,“实”指的是直接访问物理地址,“保护”指的是通过描述符表进行访问权限的保护。
长模式下描述符扩展为16字节,兼容模式下不进行这种扩展
2.系统段,段描述符和门
系统段:TSS(Task-state Segment)和LDT,称为系统段。其余的则是运行时环境包含的代码、数据、栈这等段。GDT不视作系统段因为其不通过段选择子访问。
门(Gate):特殊的段选择子,通过门进行的调用可以进行特权级别的转换。包含过程调用、中断、陷阱、任务等。
- 调用门:可以执行更高特权级别的代码,还可用于16-32位代码段的相互访问。
门的使用方式和段选择子类似,通过门选择子查询GDT或LDT中的门描述符以获取基址,然后结合偏移量访问对应的数据。不过,门提供了特权级别的转换甚至是字长模式的转换,因而是一种特殊的段描述符。
系统段,称其为“系统”,是相对于“应用”而言的。系统段的存在是为了支持操作系统的运行,包括任务上下文保存、地址管理、中断处理等。
长模式下,调用门可以用于64位和32位模式的代码段的相互访问。任务切换门被设置为NULL,其余门(包括TSS选择子和LDT选择子)被扩展为16字节。不过,页表中的特权控制很大程度上代替了门的特权控制功能。如同之前一样,段描述符和门都是在保护中重要,而在长模式中不再重要的概念。
3.任务状态段(Task-State Segment)和任务门(Task Gates)
任务状态段包含了一个任务所需的上下文:
- 通用寄存器
- 条件码:EFLAGS
- 程序计数器:EIP
- 堆栈指针(3个特权级各一个)
- 页表基址寄存器(CR3)
- 局部描述符表选择子
每次任务切换,操作系统都要保存状态,通过GDT选择新TSS并加载状态。
任务状态段要么通过TSSs(任务状态段选择子)访问,要么通过任务门访问,后者可以提供特权控制。
长模式下,不再能通过硬件切换任务,因此任务门不再有效。不过TSS仍然保留,且TSSs设置为指向TSS基址。
任务状态段的存在是为了支持任务切换,而任务切换是为了支持多道程序。一个TSS保存的内容就是一个完整的上下文,包括当前的数据、状态、执行位置等基础信息,还包含其地址空间信息(页表基址寄存器和LDT选择子)。
4.中断和异常处理
外部中断(指外设引发的异步中断),软件中断和异常都通过中断描述符表(IDT)进行管理。
- 中断描述符:IDT中的表项,都是门描述符,包含了中断处理程序的地址、特权级别等信息,也可以是一个任务门。
- 中断描述符表寄存器(IDTR):用来存储IDT的线性地址基址。
- 中断向量:中断描述符的索引,通过中断向量查询IDT中的门描述符。
外设、处理器、软件都可以引发中断。软件中断使用INT系列或BOUND指令。三种形式的中断例如:键盘中断、浮点异常、系统调用。
中断和陷阱会的处理等效于通过调用门调用处理函数,而指向任务门的中断向量会通过任务切换调用相应的处理函数。
5.内存管理
处理器支持物理地址或虚拟地址两种模式。分页启动时,所有的访存都是通过页表完成的。
- 分页(Paging):一种地址管理方式,将线性地址按照一定大小(通常是4K)映射到物理地址。这个映射往往是乱序的。
- 页表(Page Table):管理线性地址到物理地址的映射关系的数据结构。
- 页帧(Page Frame):物理内存中的页大小的连续区域。
- 页表基址寄存器:用来存储页表的地址基址,是一个控制寄存器(Control Register,CR),即CR3。
- 页表条目:包含页或下一级页表的基址,以及访问权限等信息。
长模式下的页表分为4级,每级512个条目,每个条目8字节,每个页表恰好占用4K。页表基址寄存器指向最顶级页表的物理地址基址。
6.系统寄存器
系统寄存器保存了对于操作系统运行至关重要的信息,通常涉及底层的数据结构基址和当前的系统配置。
- 条件码寄存器(EFLAGS):包含了一些标志位,用来表示上一条指令的执行结果。例如进位标志、溢出标志等。还包含模式切换中断处理等标志
- 控制寄存器(CR):包含了一些控制系统行为的标志位。例如分页开关。
- 任务寄存器(TR):用来存储TSS选择子,用于任务切换。
- 描述符表寄存器(DTR):LDTR,IDRT,GDTR指向这些描述符表的基址。
- 调试寄存器(DR)、模型指定的寄存器(MSR)等
除EFLAGS外,大多数操作系统中,系统寄存器仅限RING0使用(最高特权)。这进一步体现了其作为“系统”的能力。
长模式中,大多数寄存器都被扩展为64位,此外增加了可以读写任务优先级寄存器(TPR)的CR8。兼容模式下的DR0-DR3的地址匹配粒度仍然为64位。长模式增加了一些MSR用于支持长模式的系统指令。
7.其他资源
其他资源包括操作系统指令,性能监控计数器,内部高速缓存和缓冲区等。
综述
这一部分,我们迅速的浏览了一下处理器体系结构的组成部分,然而对于其中的细节我们还一无所知。之后,我们将会在内存管理、任务切换、中断处理等上下文中看到这些数据结构是如何具体被操作系统使用的。
值得强调的是,目前为止我们接触的大部分内容都是32位世界的产物,他们包含了一个计算机从1MB的拘谨空间到4GB的广袤世界所必须的诸多基础设施,然而他们中的很多,在今天看来,是一种过分“间接”的设计。随着硬件制造能力的提升,许多曾经的设计成为了工程上的包袱。因而,在64位世界中的内容与32位世界中的内容有很大的不同。
不过,这部分内容仍然是我们了解计算机硬件体系结构的基础,其中提到的基础概念和基本思想(描述符表、分段、任务切换、中断处理)等内容将在操作系统中起到至关重要的作用。并且,他还提供了系统引导阶段必不可少的知识准备,我们将在那里看到上述所有这些设施是如何被初始化的。
运行模式
在最开头,我已经简要的论述了Intel处理器支持的几种模式。除了实模式、保护模式、长模式,还有其他几种模式:
- 系统管理模式(System Management Mode,SMM):电源管理或原始设备制造商(Origin Equipment Manufacturer, OEM)使用的模式
- 虚拟8086模式(Virtual-8086 Mode):用于执行一些16位代码。之所以称其为虚拟,是因为8086原则上是采用实地址系统,为了在现代机器上运行这些代码,需要进行相应的配置。
当然,长模式还有一个兼容子模式和一个纯粹的64位模式。相对来说,实模式和保护模式的切换是我们最关心的,这是因为(读书笔记要求上是这么说的)它不仅是操作系统系统运行时进行的第一个模式切换,更是之后所有模式的基础。通常来讲,系统上电时默认处于实模式,BIOS会将引导扇区的文件读入内存然后加载操作系统。系统引导首先做的事情就是准备切换到保护模式。
从实模式切换到保护模式
Intel手册在后面的章节详细的描述了实模式到保护模式的切换过程。这里,我们将暂时把参考书目切换为《X86汇编语言:从实模式到保护模式》,并简要概括这个过程。
准备好全局描述符表的内容之后:
- 1.关闭中段并清空段寄存器
- 2.使能A20地址线,允许访问1MB以上的内存
- 3.加载全局描述符表(GDT)
- 4.设置CR0,使能保护模式,这是我们第一次使用32位寄存器(通常用%eax做源操作数)
- 5.使用长跳转指令,该条指令应当紧跟先前的指令以清空之前的指令流水线,之后的指令将会以保护模式取指执行。
- 6.设置段寄存器,使得段寄存器指向GDT中的段描述符
- 7.设置栈区,通常把栈区设置在引导位置之下,即0x0000~0x7c00
从实模式切换到实模式
从保护模式切换到实模式,要进行类似的过程, 以维护正确的寻址方式和寄存器指向。
- 关闭中断
- 如果启用分页,跳转到一个直接映射的程序段(线性地址等于物理地址),并且确保GDT和LDT也在直接映射的程序段内,清空CR0的PG位以关闭分页,然后将0H移动到CR3以刷新快表(TLB)
- 将段寄存器指向合适的选择子以便在实模式下可用
- 清空CR0的PE,切换到实模式
- 出于和之前一样的原因,执行一个长跳转指令
- 加载段寄存器的值以便在实模式中使用
x86系统指令寄存器
系统指令寄存器,如同前面所说的,是保存着操作系统运行所需的关键内容的寄存器。事实上,基本上也只有操作系统有修改甚至访问这些寄存器的权限。读写对应寄存器的指令通常都是特权指令,只有在RING0才能执行。
在操作系统层面,比较重要的几组寄存器包含标志寄存器、内存控制寄存器、控制寄存器。
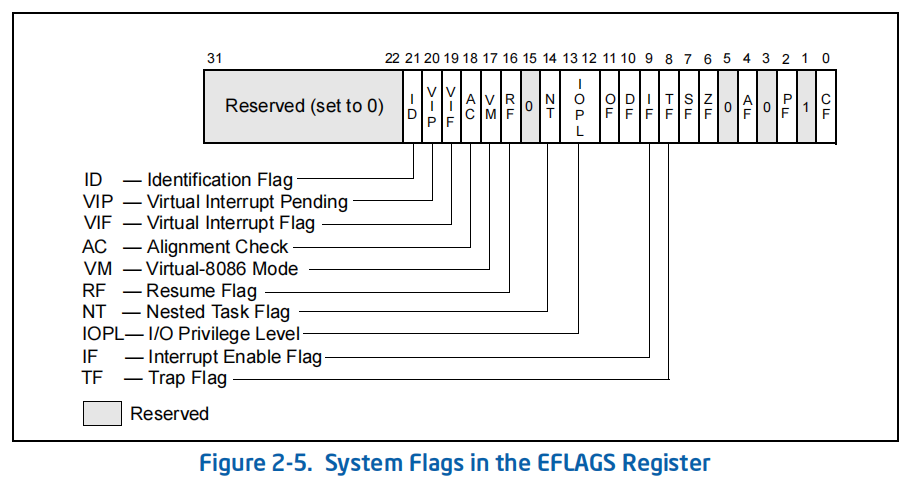
1.标志寄存器
标志寄存器包含了上一条算数运算造成的溢出、补码溢出、0、奇偶位等内容。应用程序可以通过一些用户指令来访问相应的字段。不过,标志寄存器也保存着当前系统相关的信息,例如调试模式、中断控制等、IO特权级别等信息。这些信息只能通过系统指令来访问。
2.内存管理寄存器
这些寄存器用于保存系统全局或某个任务的寻址信息,因此称之为“内存管理寄存器”,主要的内容就是之前提到的几个表结构的基址以及限长。由于TR和LDTR是特殊的系统段,还保存了他们的段选择子和段描述符属性。
这几个寄存器的内容如下所示,注意观察其中LDTR、TR和GDTR、IDTR的结构区别:
其中:
- 基址指的是表/段的首个字节(0字节)的线性地址,限长指的是表/段的最大长度
- 处理器上电或复位时会将他们的(段/表)基址设置为 0,(段/表)限长设置为 OFFFFH。(GDT和IDT不是段)
- TR和LDTR会在任务切换时自动加载,然而并不会自动进行保存。
- 每个寄存器都有对应的L/S指令用于加载(Load)或存储(Store)寄存器的值
- 通过专门的加载指令TR和LDTR加载这两个寄存器时,只需要指定一个选择子,段基址、段限长和段描述符属性会根据这个选择子从GDT中加载
接下来是具体内容:
全局描述符表寄存器 (GDTR) : 保存32/64位的GDT基址,16位的表限长。切换到保护模式时需要重新设置GDTR。
局部描述符表寄存器 (LDTR) : LDTR 寄存器保存一个16位的段选择子,32/64位的LDT段基址、LDT段限长和 LDT 的描述符属性。包含LDT的段也必须在GDT中有一个表项。(因为加载时要通过这个表项补全信息)
中断描述符表寄存器 (IDTR):IDTR 寄存器保存IDT 基址和16位的表限长。
任务寄存器(TR):任务寄存器保存一个16位的段选择子、基址、段限长以及当前任务的 TSS 的描述符属性。
3.控制寄存器
控制寄存器(CR0~4)确定处理器的运行模式和当前执行任务的特征。在保护模式和兼容模式下,这些寄存器都是 32 位的。
长模式下,寄存器扩展到64位,MOV CRn指令可用于修改值,bwlq等后缀被忽略,但还有一些特殊规定,例如CR0和CR4的高32位,CR3的40-51位必须被置为0.
此外,增加了CR8
- CR0:含有控制处理器操作模式和状态的系统控制标志
- CR1:保留
- CR2:含有导致页错误的线性地址
- CR3含有页目录表物理基址地址,因此该寄存器也被称为页目录基地址寄存器PDBR
系统指令
8条系统指令对应于四个内存管理寄存器的Load Store操作:
| op | GDTR | LDTR | IDTR | TR |
|---|---|---|---|---|
| Load | LGDT | LLDT | LIDT | LTR |
| Store | SGDT | SLDT | SIDT | STR |
注意,其中LLDT和LTR会自动加载段选择子对应的信息到这两个寄存器里
软件构造-git和软件版本管理
GIT的项目结构
git的项目由工作区/暂存区/本地仓库/远程仓库几部分组成, 各部分之间通过下列指令进行文件的传输.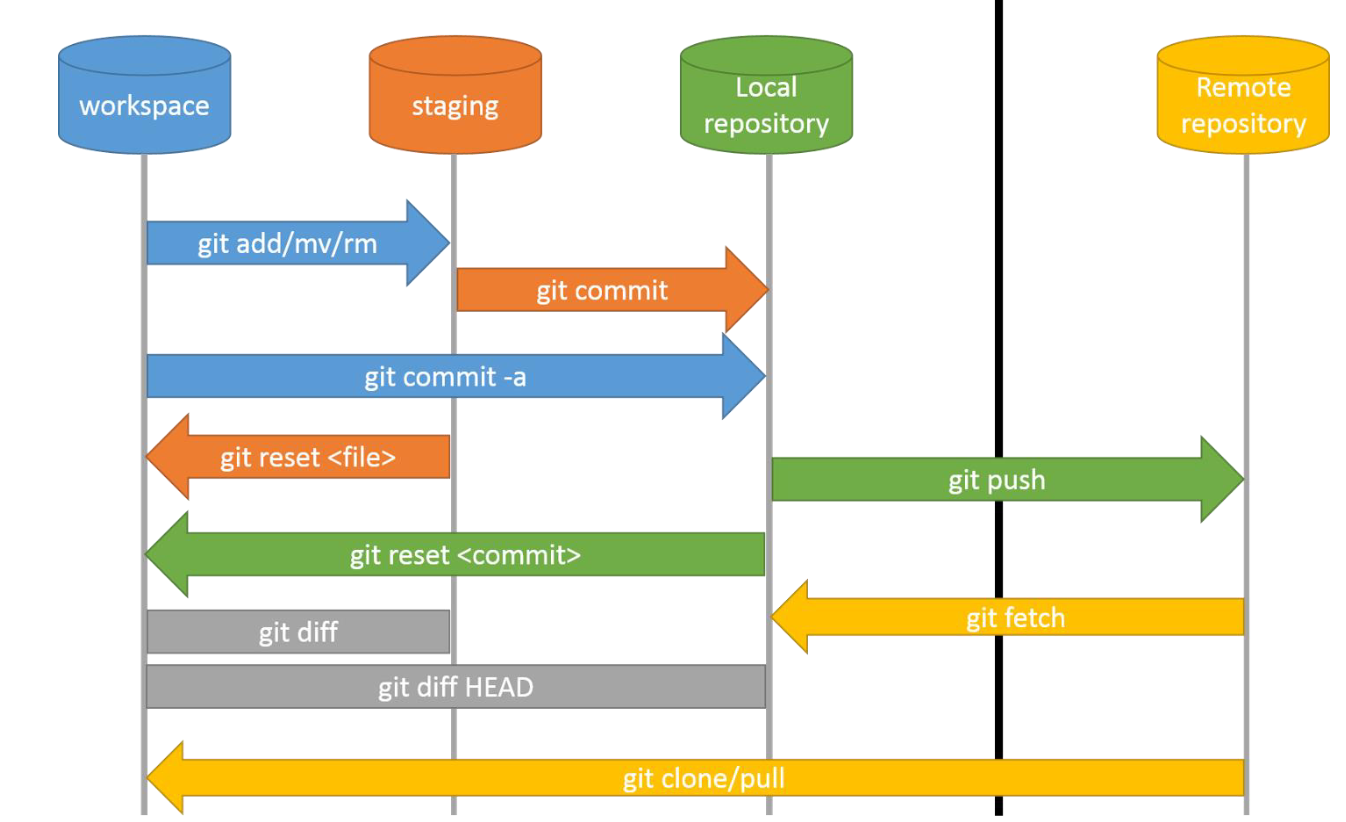
git内部将commit表示为一张图,每个commit都指向它的父commit.一个commit可以有0个(最初的commit),1个(一般情况),2个(merge)父commit,同样一个commit也可以由0个(最后的commit),1个(一般情况),2个(branch分叉点)子commit
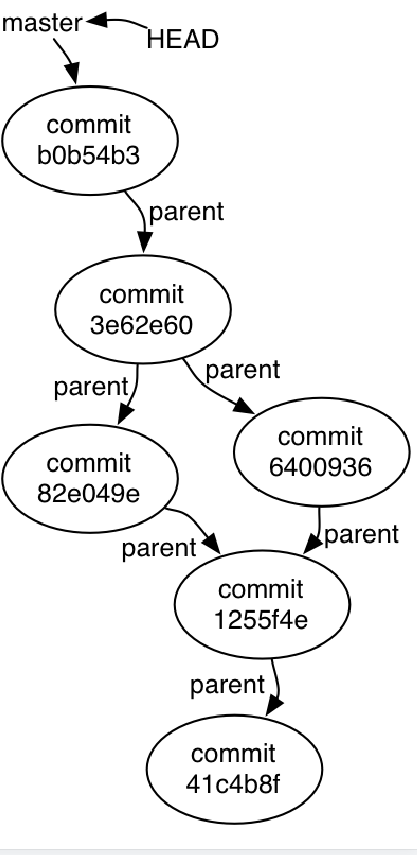
一个分支就是一个指向某个commit的指针,HEAD指向当前分支,当commit时,HEAD指向新的commit,分支指针不变.一个分支指针总是指向当前分支的最新提交,合并后,被合并的分支不再继续”前进”,除非它又进行了新的提交.
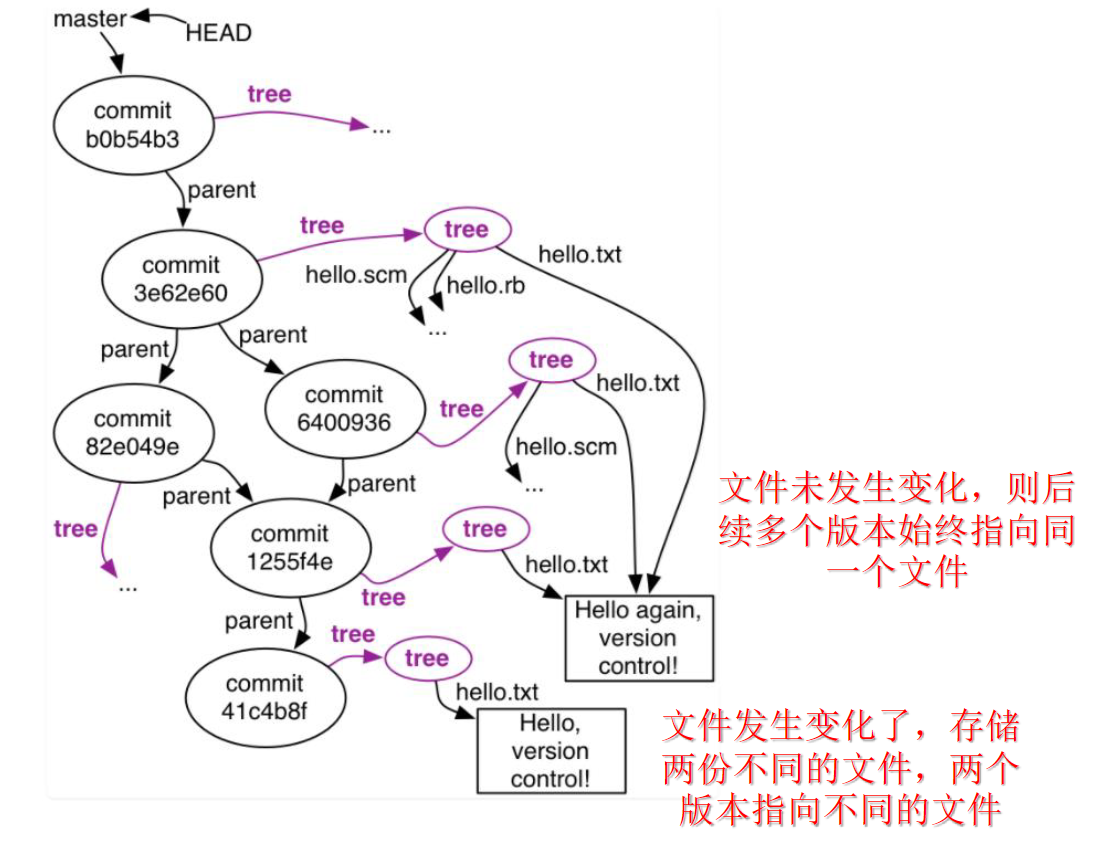
git是以文件为单位进行存储的,而是以文件为单位进行存储的,不同的文件存储一份,如果之后不发生改变,就不在下一个commit中存储,而是直接指向之前的文件记录.
软件构造-软件构造的模型
软件构造的传统模型及其阶段
软件构造的模型,就是指对软件构造的流程的一个抽象概括。每个模型包含许多阶段,各阶段完成一定的任务,按照模型的顺序进行各阶段的任务,就能推进软件的构造,实现软件的开发和维护。
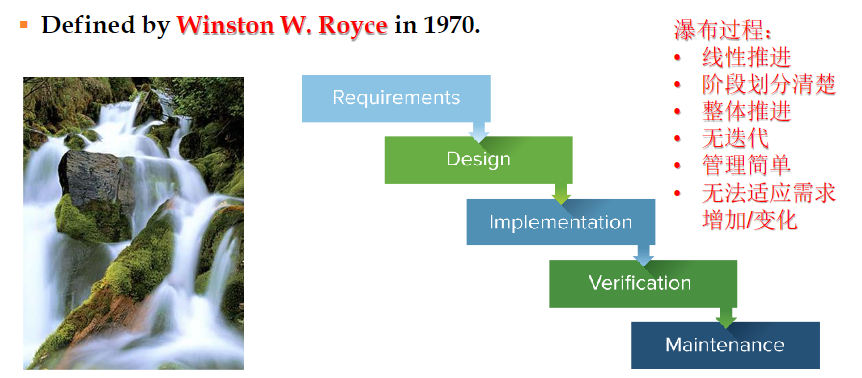
瀑布过程
瀑布模型是一种线性模型,不进行迭代。按照需求-设计-实现-验证-维护5各阶段一次推进,管理简单,但难以适应需求变化。
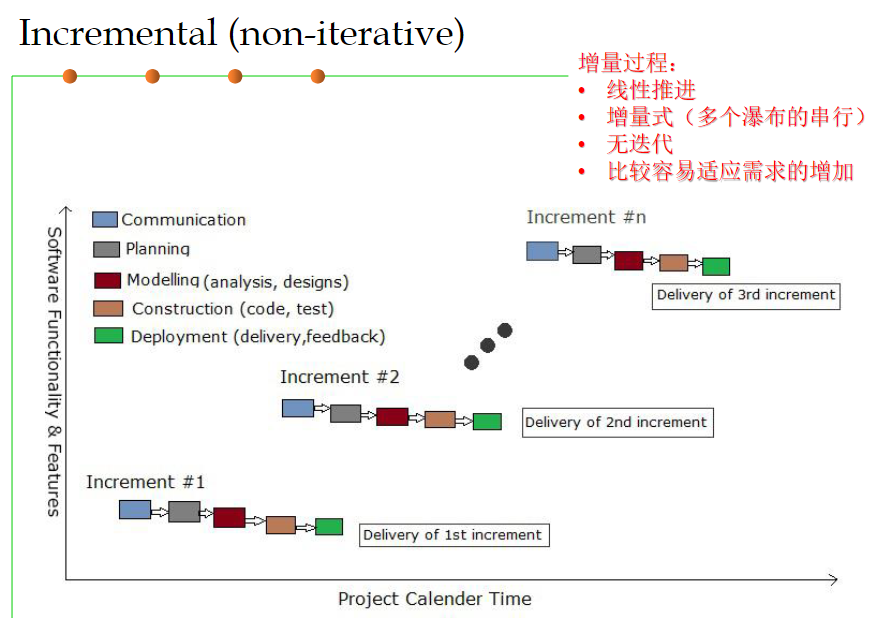
增量过程
增量过程是一种线性模型,它同样不进行迭代,但是通过将原先的“大瀑布”拆分成数个“小瀑布”,逐步地完成软件开发,增强了对变化需求的支持性。增量开发的五个阶段分别是沟通、计划、模型化、构建、部署。
V字模型
V字模型可以被视为是瀑布模型的一种扩展,它不是线性结构,而是在完成逐级构建之后,又通过逐步测试“上升”到开发阶段。V字模型突出了测试阶段和开发阶段的一一对应关系。V字模型的左侧是项目定义阶段,包含操作概念界定、需求和架构分析、细节设计。底部是代码实现。右侧是测试和集成阶段,包括集成与测试、系统验证、操作和维护。
V字模型从左到右是时间上的逐步完善,从下到上是设计上的逐步抽象。当进行到最右上时,经由反馈,重新回到最左上。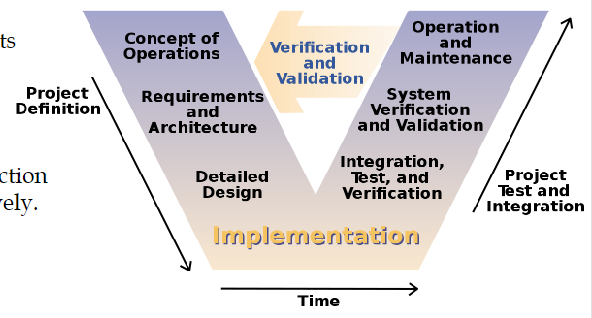
原型模型
原型模型包括分析、原型实现、设计、实现、测试、维护6个阶段,在瀑布中加入了一个原型阶段,该阶段将反复根据客户的需求进行迭代。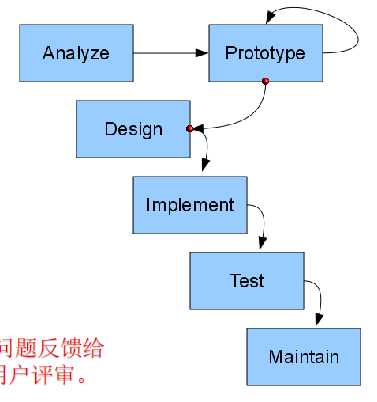
螺旋模型
螺旋模型是瀑布阶段和原型模式的结合,在一次螺旋中完成一个瀑布,产出一个原型,然后经过对原型的测试进入下一个阶段。螺旋模型的四个阶段分别是需求分析、风险分析、开发和测试、计划下一次迭代。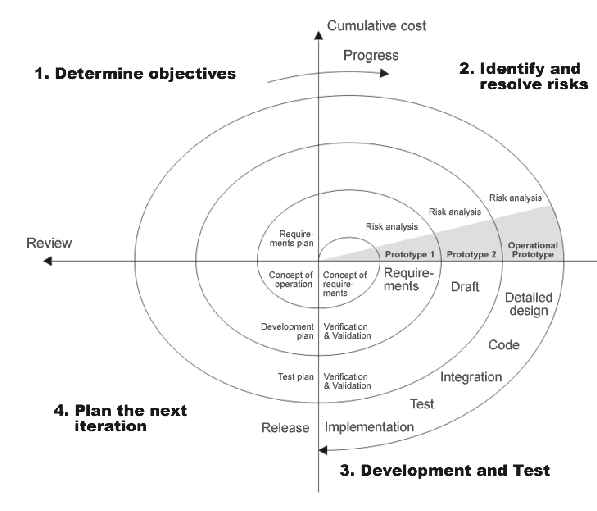
敏捷开发与极限编程
敏捷开发就是指通过快速迭代和小规模增量以快速适应变化,一次敏捷开发的迭代持续1~4周,进行迭代计划、测试和增量开发、迭代评审、迭代回顾、更新产品活动。
敏捷开发的核心是迭代和反馈,迭代是指在一次迭代中完成一次小规模的增量开发,反馈是指在迭代过程中,通过评审和回顾,及时发现问题,及时进行调整。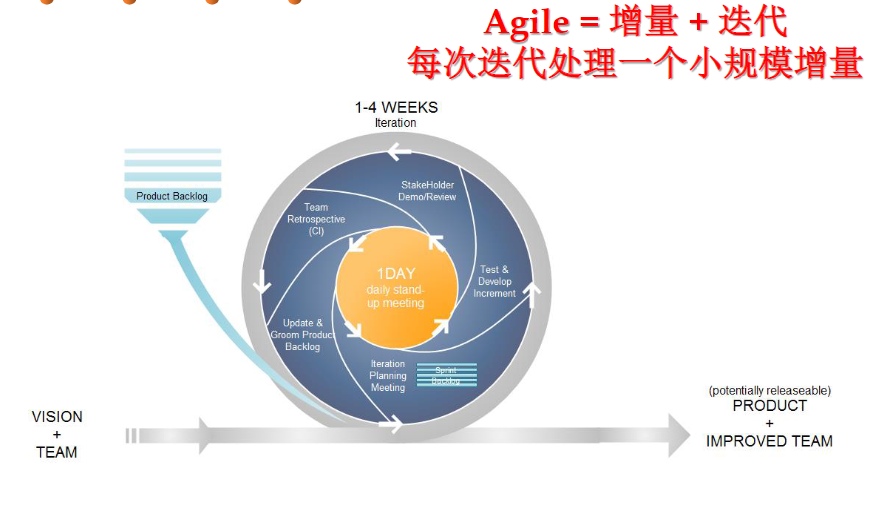
极限编程包括极限的用户参与,极限的小步迭代,极限的测试与验证。概括来说,就是对敏捷开发思想的提炼。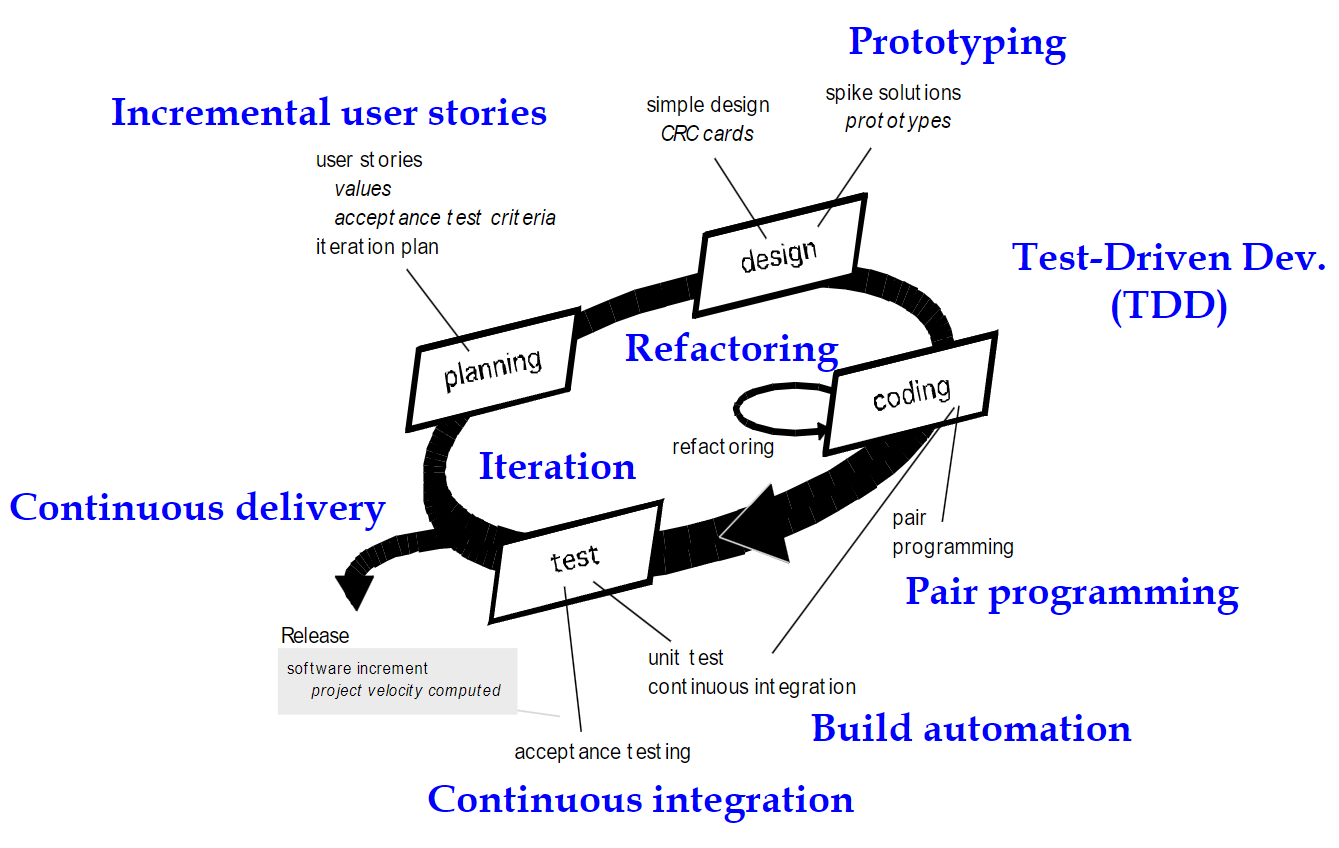
软件构造-3维度8视图及软构基本理念
软件三维度八视图
软件描述的三个维度分别是:Code/Component, Run-time/Build-time, Moment/Period
分别对应于空间、时间、状态。从局部代码的角度来看能看到软件的内容,从整体组件的角度来看能看到代码的结构。一个软件可以是静态的程序,也可以是动态的应用。一个软件具有某一时刻的状态,在一段时间内具有一定的行为模式,这就构成了基本的三个维度。
| Period | Moment | |||
| Code | Component | Code | Component | |
| Build-time | Source code, AST | Package, File, Test case, Build Script | Code Churn | Configuration Item, Version |
| Run-time | Code Snap, Memory | Package, Dynamic Linking, Network, Hardware | Execution Trace, Multi-Thread | Event log, Multi-Process |
| Sequence Diagram | ||||
各象限的内容浅析
构建时,代码视角,时间点:源码、AST、语意
代码是程序的最基本内容,一个代码经过词法分析和语法分析得到抽象语法树,进而对应某种机器的形式化操作。而原始的源代码对应的功能,即语意,则是程序员希望达到的目标。
构建时,组件视角,时间段:包、文件、测试用例、构建脚本
一个程序要想构建起来,仅有源代码是不够的。程序必须按照一定的规则组织成包、模块、编译单元等编译系统支持的结构,配合依赖的库文件,经过构建脚本的处理,才能得到可执行的程序。静态链接和运行测试用例也是在构建时进行的。
构建时,代码视角,时间段:代码变更
代码变更是以行为单位的增、删、改,是代码的最小变更单位。代码变更的频率和代码的质量有很大的关系,代码变更的频率越高,说明代码的质量相对较差,需要不断的改bug或改需求。
构建时,组件视角,时间段:配置项、版本
软件配置项是更宏观的软件管理单位,例如Git将文件作为软件配置项。软件版本则是特定时间下所有软件配置项的综合体,是软件的一个快照。软件版本管理通过记录软件配置项的变更,并维护软件版本中的软件配置项的内容,来实现记录软件开发的历史。
运行时,代码视角,时间点:代码快照、内存
运行时的代码快照图是对代码当前引用和对象内容的一个抽象展示,体现出引用和对象是否可变,包含哪些内容,经历过哪些变化。内存则包含代码运行时的具体数据。
运行时,组件视角,时间段:包、动态链接、网络、硬件
部署图展示了软件在运行时如何进行机器间的业务交互,通常是展示了包含网络通讯和远程服务的情况下,各中间节点机器的OS、软件支持、代码模块、代码逻辑,以及他们之间的数据链路。
运行时,代码视角,时间段:栈追踪、多线程
代码中的调用栈信息可以展示出代码是如何一步步地进入当前函数的,常用于调试。
运行时,模块视角,时间段:事件日志、多进程
事件日志提供了宏观视角下的软件运行情况,可以用于分析软件的性能瓶颈和问题原因。
软件构造的阶段
1.从无到代码:程序员设计代码
2.从代码到模块:程序员设计软件结构
3.从构建到运行:程序员将软件部署在设备上
4.从时间点到时间段:运行软件,获取结果和日志
软件设计的五个核心维度
核心:
避免错误
易于理解
便于修改
其余:
高效开发
高效运行
软件构造-OOP中类的关系关联/依赖
OOP中对象的关系
在面向对象编程(Object-Oriented Programming,OOP)中,”delegation”(委托)、”association”(关联)、”composition”(组合)和”aggregation”(聚合)是几个重要的概念,用于描述对象之间的关系。
委托(Delegation, A uses B):
委托是一种对象之间的关系,其中一个对象将某些任务委托给另一个对象来完成。在委托关系中,一个对象将一部分功能交给另一个对象处理,通过委托可以实现代码的复用和模块化。委托关系通常是动态的,可以在运行时进行修改。
依赖关系(Dependency, A uses B):
依赖关系表示A的某些方法依赖于B的行为。在使用依赖实现的委托中,A接受一个B类型的参数,并将行为委托给B:
关联(Association, A has B):
关联是对象之间的一种关系,表示对象之间的连接或联系。关联关系可以是单向或双向的,可以是一对一、一对多或多对多的。关联关系通常用于描述对象之间的交互关系。
组合(Composition, B is part of A):
组合是一种强关联的关系,表示一个对象是由其他对象组成的整体,对象之间具有“整体-部分”的关系。在组合关系中,部分对象无法独立存在,它们的生命周期与整体对象相互依赖。如果整体对象被销毁,部分对象也会被销毁。
通常表现为静态初始化的字段, 不可通过外部方法更改.
聚合(Aggregation, A owns B):
聚合是一种弱关联的关系,表示一个对象包含其他对象,但被包含对象可以独立存在。聚合关系中,包含对象与被包含对象之间没有强依赖关系,被包含对象可以从一个包含对象中脱离出来,继续存在。聚合关系通常用于表示整体与部分之间的关系,但部分对象的生命周期不受整体对象控制。
通常表现为动态初始化的字段, 可通过外部方法更改.
委托/关联/依赖的关系
- 委托和关联/依赖的关系:在委托(Delegation)中,一个对象(委托者)将任务的执行委托给另一个对象(委托对象)。
委托对象负责执行特定的任务,而委托者可以通过调用委托对象的方法来触发任务的执行。在这种情况下,委托者需要持有委托对象的引用,以便能够调用其方法。这种关联关系要么通过
参数传递来实现, 通过字段(属性)保存委托对象的引用来实现。
前者构成依赖关系,后者构成关联关系 - 关联和聚合/组合的关系: 组合和聚合是关联的两种具体形式
组合是一种比聚合更强的关系,它表示整体对象包含部分对象,并且部分对象无法独立存在。
聚合是一种弱关系,表示整体对象包含部分对象,但部分对象可以独立存在。
小结和讨论
综上所述:
- 委托是一种设计模式, 将任务的执行委托给另一个对象.
- 通过参数进行的委托使类之间存在依赖关系.
- 通过引用进行的委托使类之间存在关联关系.
- 组合是一种强关系,同生共死, 通常在构造函数中创建,在析构函数中销毁
- 聚合是一种弱关系, 仅持有引用. 通常在外部创建,通过调用public方法保存到rep里,在外部某处销毁.
讨论:
- 委托关系的强弱? 依赖 < 聚合 < 关联 < 组合, 越强, 越不容易修改, 越发生在类的内部. 反之, 则容易修改, 并且可以发生在类的外部.
所以依赖关系是最方便修改的, 组合关系是最难修改的. - 临时委托VS永久委托? 依赖关系的委托是临时的,因为没有任何信息记录委托对象。而关联关系的委托是永久的,因为委托对象通过字段的形式保存了下来。
软件构造-关于多态-Java和C++中的子类与泛型
多态
多态指的是同一个接口可以在不同的条件下表现出不同的行为。多态通常包括三种形式:参数多态(重载、可变参数)、子类多态(重写)、泛型多态(泛型类、模板类)。
参数多态指的是一个函数可以接受不同类型的参数并做出对应的反应,在OOP语言中,这通常通过称之为“重载(overload)”的技术实现,该技术会为函数生成一个包含参数信息的签名(这个过程称之为mangle),然后在编译或解释时,根据参数信息在已存在的签名中进行匹配,如果匹配到合适的函数,就进行调用,否则就是一个编译错误。
子类多态指的是一个子类可以使用和父类同名的方法,但是执行与父类不同的行为。这是通过称之为重写(override)的技术实现的,在子类上调用函数时,编译器或解释器优先选择子类的函数执行,而非父类。一个更常见的用法是用一个父类或抽象类引用存储一个对象,然后调用他的某个方法。该方法会在不同的具体类型上进行不同的操作。
泛型多态指的是某种算法、操作、数据结构可以应用在不同的类型上,这通常是使用泛型类的技术实现的,泛型类接收一个类型参数,并对参数做某种限制(比如要求它必须是可比较的),使用这个类型参数声明一些方法或变量,以实现针对任意满足条件的类型进行相同的操作。
下面我们就来看看Java和C++的具体技术。
重载
java和C++的重载都是通过在编译时进行mangle并解析函数调用完成的。不同的是,C++中的函数声明具有类作用域,换言之,子类不能重载父类的方法。这被称之为“覆盖”。如果子类声明了一个和父类名称相同但参数不同的方法,将不能通过子类调用父类的该方法。解决方法是使用using关键字将父类方法的在子类作用域内声明,这样处于同一个作用域的方法就可以构成重载关系了。
而在Java中,子类可以重载父类型的方法,无需特殊操作,也不会覆盖父类型方法。
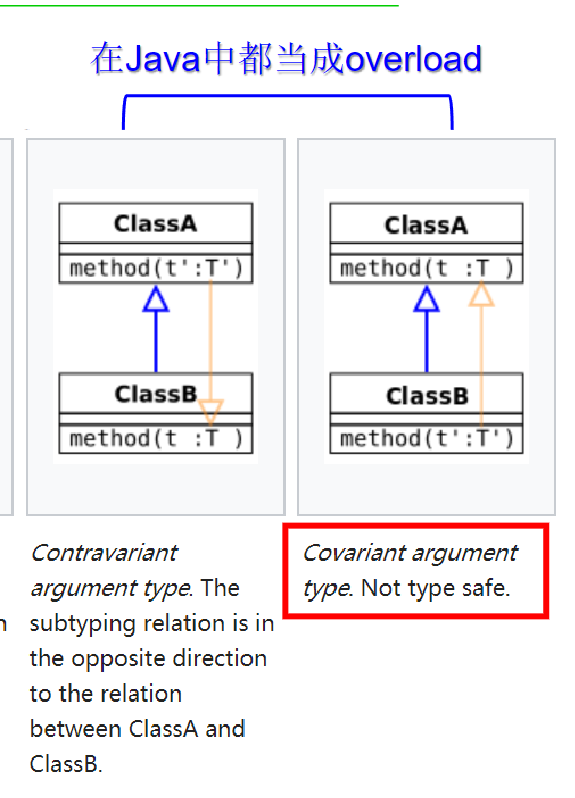
重写
java和C++都支持子类任意的重写父类型的方法,并且都要求返回协变的类型,都不支持逆协变参数的解析。不过这里有一个微妙的区别:动态绑定和静态绑定。在C++中,使用父类引用调用方法并不会自动的调用子类方法。只有使用子类引用才能访问子类的方法。解决办法是给函数增加virtual关键字,这将让编译器生成一张虚函数表。在调用时,在虚函数表中访问对应的函数指针进行调用,子类的虚函数比父类优先级更高,因此如果子类重写了方法,就会调用子类的方法。这被称之为“动态绑定”。
在Java中,会自动进行动态绑定。
泛型
java使用类型擦除的技术实现泛型,即生成一个泛型类,在类内将所有泛型参数转换为Object类型(或规定的父类)。而C++的模板使用展开替换技术实现泛型,即生成许多模板特化,针对不同的类型调用不同的模板。对于Java而言,一个原始的泛型(没有类型参数的泛型)和所有的泛型实例化都具有相同的类型。而对于C++而言,未特化的模板和全特化的模板是完全不同的类型。
为了在C++中能实现泛型多态,即java中List<?>这样的操作,可以让模板类继承一个普通类。由于所有模板类的特化都会继承这个普通类,就可以用这个普通类的引用访问任何模板类了。
软件构造-李氏原则漫谈"
李氏原则
李氏原则的核心思想就是:所有父类出现的地方,子类都可以出现。
在解释这句话的含义之前,我想请读者回忆一下C标准中的类似表述:一个整形表达式可以出现在任何整形字面量可以出现的地方。可以说,这种表述就是定义了行为的完全兼容性。
这句话的含义有五个方面:

概括来说,就是规定了子类型的函数规约和函数签名应当满足的条件。函数规约应该保持或加强,而函数签名应该兼容。
具体而言,子类型的返回值应当是父类型返回值的子类,子类型的参数应当是父类型的参数的父类,子类型不应抛出新的必检异常,可以抛出原先的必检异常及其子类。下面是Java对于重写的语法要求:

可以看到,基本的思路是一致的,不过由于java中不同的函数签名被视为不同的函数,所以“参数逆协变”的行为子类重写被视为重载。也是因为如此,java不会检查子类方法是逆协变的还是协变的。但为了编写一个行为子类,我们需要手动的保证这点。
软件构造-关于表示泄露2-进阶体会
我们上次讨论了关于表示泄露的三种基本形式:访问权限、getter传递引用、constructor接收引用,这次来讨论更加细节的内容
原创性声明:每一个字都是我手敲的。
更加间接的表示泄露-来自浅拷贝
我们对一个引用类型(对象)进行拷贝时,有三种做法。
- 引用拷贝, 通常通过
=运算符实现。两个引用变量将指向同一个内存地址。 - 浅拷贝,一些方法提供了浅拷贝。我们把一个对象的字段值全部拷贝到另一个对象里,然后把这个对象的引用赋值给新的引用
- 深拷贝,一些方法提供了深拷贝,通常需要手动实现。对于基本数据类型字段,我们把值拷贝到另一个对象;对于引用类型字段,我们
把这个字段深拷贝到另一个对象的这个字段中,最后把新的对象的引用赋值给新的引用。
这三个概念有些抽象,我们必须结合一些例子来进行讲解。但是我们可以先注意一点:引用拷贝是一次赋值,浅拷贝对字段遍历赋值,深拷贝是对字段递归地赋值。
如果防御性拷贝只是浅拷贝,那么依然存在风险,考虑如下代码:
1 | class qaq{ |
和如下的客户端程序
1 | public static void main(String[] args) { |
现在,q中的a字段的第零个元素的label还会是1嘛?答案是否定的。
究其原因,是因为 qaq.getA()返回的是对LinkedList类型的浅拷贝,这个类型中存放的内容是waw,一个可变引用类型。
因此,当我们对浅拷贝(对应qaq.getA())调用getter(对应get)获取一个可变引用,再对这个引用调用mutator(对应setLabel)
时,就会把拷贝的母本中的对象也修改!
再次体会一下这个逻辑:母本中的内容是一个引用,我们通过浅拷贝获取了这个引用,修改了引用对应的对象,于是母本的内容虽然没有改变,但是母本的内容指向的对象却发生了改变。
这已经很抽象了!为了避免这个方法,对于任何可变类型的List,Map等,在拷贝时要特别注意深浅。如果是List
一些探讨-public final会导致rep exposure吗?
MIT的课件中说表示泄露“meaning that code outside the class can modify the representation directly.”,
不过我认为这是不准确的,即使不能修改ADT的表示,而仅仅能够获取ADT的内部结构,客户端也足以让ADT的抽象性泄露。
我们考虑下面这个数据结构:
1 | /** Represents an immutable right triangle. */ |
其中,HYPOTENUSE被定义为是public static final int,因此它是作为一个不可变类属性。然而,其访问权限是public,这
意味着用户将有可能使用这个特殊的成员。比如说,编写一些依赖于HYPOTENUSE的代码,而一旦这个值改变,那么这些代码都需要进行修改!
要注意,“斜边存储在边数组的哪个位置”完全不是这个ADT应该暴露出来的东西,因此,尽管它是不可被修改的,但是它依然会导致表示泄露。